Loading... # 向量、栈和队列 ## 线性表 ### 线性表的抽象数据类型 线性表是n $ n(n \ge 0) $个数据元素组成的有限序列 $k_0, k_1, k_2, k_3, ..., k_{n-1}$其中$k_0$为开始结点,没有前驱,$k_{n-1}$为终端结点,没有后继。当$n=0$时称为空表。**线性表中的各个数据元素并不要求是同一种数据类型**。相同数据元素组成的线性表为向量。 * 串:数据元素是单个字符,字符向量 * 文件:数据元素是组合项,且数据类型不同 线性表的基本运算 * 表的初始化,即生成一个空表; * 判断表结点个数是否零; * 判断表结点个数是否为最大允许个数; * 求表中结点个数 * 取表中第*i*个结点 * 查找表中值为*x*的结点 * 在表中第*i*个位置上插入一个新结点; * 删除表中的第*i*个结点。 ### 线性表的结构表示 可以用顺序存储,可以用链接存储,也可以用散列存储,必要时还可以用索引存储。 ```cpp typedef int ElementType; #include <stdio.h> #include <stdlib.h> #include "list.h" struct linearList { ElementType * data; int MaxSize; int Last; }; typedef struct linearList LinearList; vold InitList(LinearLsit *L, int sz) { if (sz > 0) { L->MaxSize=sz; L->Last=0; L->data=(ElementType *)malloc(sizeof(ElementType) * L->MaxSize); } } void FreeList(LinearList *L) { free(L->data); } Bool ListEmpty(LinearList *L) { return (L->Last <=0>)?TRUE : FALSE; } Bool ListFull(LinearList *L) { return (L->Last >=L->MaxSize)?TRUE:FALSE; } int ListLEngth(LinearList *L) { return L->Last; } ElementType GetElem(LinearList *L, int i) { return(i< 0 || i > L->Last)?NULL : L->data[i]; } int LocateElem(LinearList *L, ELementType x) { int i; for (i=0; i<L->Last; i++) if(L->data[i]==x) return i; return -1; } Bool InsertElem(LinearLsit *L, ElementType x, int i) { int j; if (i<0 || i>L-Last||L-last==L->MaxSize) return FALSE; else { for (j = L->Last - 1; j >=i; j--) L->data[j+1]=L->data[j]; L->data[i]=x; L->Last++; return TRUE; } } Bool DeleteElem (LinearList *L, int i) { int j; if (i<0 || i >=L->Last||L->Last==0) return FALSE; else { for(j=1;j<L->Last-1;j++) L->data[j]=L->data[j+1]; L->Last--; return TURE; } } void printout(LinearList *L) { int i; for (i=0;i<L->Last;i++) printf("%d", L->data[i]); printf("\n"); } ``` ## 向量 ### 向量的抽象数据类型 向量是由同一种数据结构类型的数据元素组成的线性表,因此向量的逻辑结构与一般线性表的逻辑结构是相同的。其数据元素可以是初等项,也可以是组合项,甚至是一种数据结构。 向量元素按它们之间的关系排成一个线性序列$a_0,a_1,a_2,...,a_{n-1}$(差一性) 向量在数组空间中是顺序存储的,物理上的邻接关系隐含地体现了元素逻辑上的邻接关系。设数组存储空间的始地址为addr,一个向量元素存储空间大小为$l$,用$Loc(a_i)$表示向量元素$a_i$的存储始地址,则有$Loc(a_i)=addr+i \times l$。由上可知求任意一个向量元素的存储地址所花费的时间都相等。因此,这种存储结构是一种随机存储结构。 ### 向量的插入和删除 * 插入后移语句的平均执行次数$\sum_{i=0}^n \frac {n-i} {n+1} =\frac n 2 $ 时间复杂度为$O(n)$ * 删除前移语句的平均执行次数$\sum_{i=0}^n \frac {n-1-i} {n} =\frac {n-1} 2 $ 时间复杂度为$O(n)$ ### 求集合的并运算和交运算 * 对于并运算,假设Va长于Vb: * 最少比较次数是Va的前m个结点分别与Vb中的一个结点等值,为:$C_{min} = \sum_{i=0}^{m-1} (i+1) = \frac {m(m+2)} 2 $ * 最多比较次数是任何结点都不等值$C_max = \sum_{i=0}^{m-1}n = m\times n $ * 最少和最多的移动次数分别为: $M_{min} = n $ , $M_{max}=m+n $ * 对于交运算 * $C_{min} = \sum_{i=0}^{m-1} (i+1) = \frac {m(m+1)} {2} $ * $C_{max} = m \times n$ * 移动操作 $M_{min} = 0 M_{max} = m vector.h ```c # ifndef _Vector_H enum bloolean {FALSE, TRUE}; typedef enum boolean Bool; struct vector { ELementType *elements; int ArraySize; int VectorLength; }; typedef struct vector Vector; void GetArray(Vector *); void InitVector(Vector *, int sz); ElementType GetNode(Vector *V, int i); void FreeVector(Vector *); int Find(Vector *, ElementType); Bool Remove(Vector *, int i); Bool Insert (Vector *, ElementType, int); Vector * Union(Vector *, Vector *); Vector *InterScetion (Vector *V, Vector *); # endif ``` vector.c ```c # include "vector.h" void GetArray(Vector *V) { V->elements=(ElementType *)malloc(sizeof(ElementType) * V->ArraySize); if (V->elements==NULL) printf("Memory Allocation Error"); } void InitVector(Vector *V, int sz) { if (sz<0) printf("Invalid Array Size\n"); else{ V->ArraySize = sz; V->VectorLength=0; GetArray(V); } } void FreeVector(Vector *V) { free(V->elements); } int Find(Vector *V, ElementType x) { int i; for (i=0; i<V->VectorLength;i++) if (V->elements[i]==x) return i; return -1; } Bool Insert(Vector *V, ElementType x, int i) { int j; if (V->VectorLength==V->ArraySize) { printf("overflow\n"); return FALSE; } else if (i<0||i>V->VectorLength) { printf("position error\n"); return FALSE; } else { for (j=V->VectorLength-1;j>=1;j--) V->elements[j+1]=V->elements[j]; V->elements[i]=x; V->VectorLength++; return TRUE; } } Bool Remove(Vector* V, int i) { int j; if (V->VectorLength==0) { printf("Vector is empty\n"); } else if (i<0||i>V->VectorLength-1) { print("position error\n"); return FALSE; } else for (j=i;j<V->VectorLength-1;j++) V->elements[j]=V->elements[j+1]; V->VectorLength--; return TRUE; } Vector * Union(Vector *Va, Vector *Vb) { int m, n, i, k, j; ElementType x; Vector * Vc =(Vector *)malloc(sizeof(Vector)); n=Va->VectorLength; n=Vb->VectorLength; InitVector(Vc, m+n); j=0; for(i=0;i<n;i++) { x=GetNode(Va, i); Insert(Vc,x,j); j++; } for (i=0;i<m;i++) { x=GetNode(Vb,i); k=Find(Va,x);/*已经有了的就不加入了*/ if(k==-1) { Insert(Vc,x,j); j++; } } return Vc; } Vector *InterScetion (Vector *Va, Vector *Vb) { int m, n, i, k, j; ElementType x; Vector *Vc = (Vector *)malloc(sizeof(Vector)); n=Va->VectorLength; m=Vb->VectorLength; InitVector(Vc, (m>n)?n:m); i=0; j=0; while(i<m){ x=GetNode(Vb,i); k=Find(Va,x); if(k!=-1) {Insert(Vc,x,j);j++;} i++; } return Vc; } ``` ### 约瑟夫(Josephus)问题 设n个人围成一圈,按一个指定方向从第s个人开始报数,报数到m为止,报数为m的人出殡,然后从下一个人开始重新报数,报数为m的人又出列......直到所有的人全部出列为止。Josephus问题要求对任意给定的n,s,m求出按出列次序得到的人员顺序表。 ```c void Josephus (Vector *P,int n, int s,int m) { int k=1, i, s1=s, j, w; for (i=0; i<n ; i++){ Insert(P,k,i); k++; } for (j=n;j>=1;j--) { s1=(s1+m-1)%j; if(s1==0) s1=j; w = GetNode(P, s1 -1); Remove(P,s1-1); Insert(P,w,n-1); } } ``` ## 栈 栈是一种特殊的线性表,在逻辑结构和存储结构上,栈与一般的线性表没有区别,但对允许的操作加以限制,栈的插入和删除操作只允许在表尾一端进行,是受限的线性表。 ### 栈的逻辑结构及其实现 * 顺序栈:顺序存储。 * 链式栈:链式存储。 栈的逻辑结构是线性表,在这里采取顺序存储,可以使用数组实现栈的存储。栈中数据元素都相同,向栈中插入一个元素称为进栈(push),删除一个元素称为出栈(push)。每次删除的都是最后进本身的元素,称为后进先出表。设置一个栈顶指针,数组的下标,top=-1表示空栈,top=MaxSize-1表示已满。 ### 栈的应用 #### 表达式的计值 在源程序的编译过程中,编译程序要对源程序的表达式进行处理。源程序中的表达式,一种含有变量,编译程序经过分析,把表达式的计值步骤翻译成机器指令序列,在目标程序运行时执行这个机器指令序列,即可求出表达式的值;另一种不含变量,即常量表达式,编译程序经过分析,在编译过程中就可立即算出表达式的值。表达式的分析和计算是编译程序最基本的功能之一,也是栈的应用的一个典型例子。 为了使问题简化,在这里只考虑常量表达式的情况,假设∶表达式中的操作数只允许为个位的整常数(若为多位数,可用.分隔两操作数);除整常数之外,只含有二元运算符+、一、*、/和括号(、);计值顺序遵守四则运算法则;表达式没有语法错误。 在源程序中书写表达式时,二元运算符在两个操作数之间,这种表示方式称为中缀式。中缀表达式的计值需要两个工作栈,一个运算符栈,一个操作数栈。编译程序扫描表达式(表达式在源程序中是以字符串的形式表示的),析取一个"单词"——操作数或运算符,是操作数则进操作数栈,是运算符则进运算符栈,但运算符在进栈时要按运算法则进行如下处理∶ 1. 当运算符栈为空时,析取的运算符无条件进栈。 2. 当栈顶为*或/时,若析取的运算符为(,则进栈;否则,先执行出栈操作,并执行(6)的操作,然后该运算符再进栈。 3. 当栈顶为+或一时,若析取的运算符为(、*或/,则进栈;否则,先执行出栈操作,并执行(6)的操作,然后该运算符再进栈。 4. 当栈顶为(时,析取的运算符除)之外,都可进栈。 5. 若析取的运算符为),则先要连续执行出栈操作,直到出栈的运算符为(时为止,实际上,)并不进栈。 6. 除了(之外,每当一个运算符出栈时,要将操作数栈的栈顶和次栈顶出栈,进行该运算符所规定的运算,并把运算结果立即又进栈。(出栈时,操作数栈不进行任何操作。 7. 当表达式扫描结束后,若运算符栈还有运算符,则将运算符一一出栈,并执行(6)的操作。当运算符栈为空时,操作数栈的栈顶内容就是整个表达式的值。例如中缀表达式2*(3+4)-8/2的计值过程如图 2.3 所示。 在实际的表达式计值中,往往采用另一种处理方法,即先把中缀式转换成后缀式,然后再对后缀式进行计值处理。 把操作数所执行运算的运算符放在操作数之后的表示方式称为后缀式。例如中缀表达式2*(3+4)-8/2的后缀式为234+*82/-。 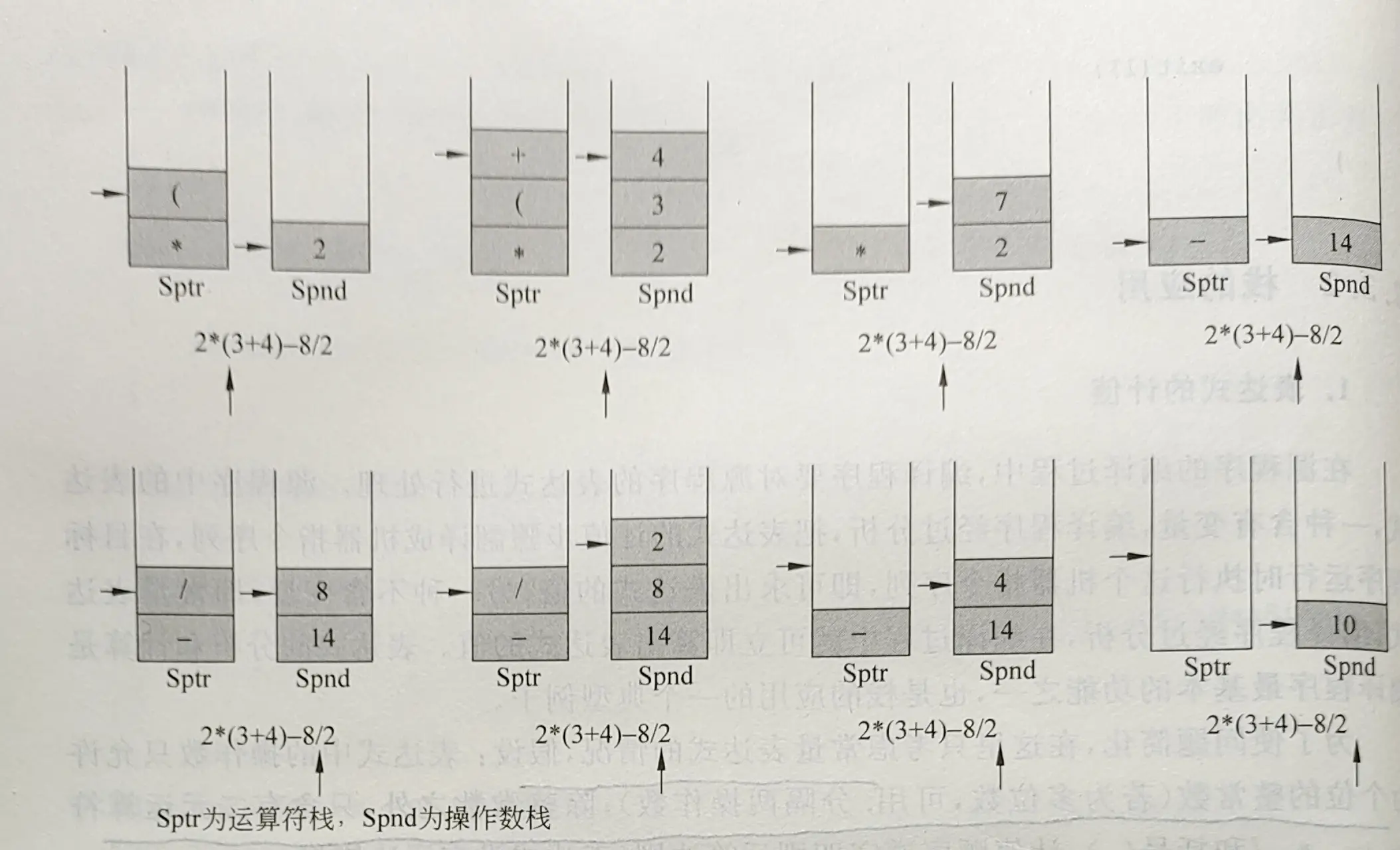 * 图2.3 中缀表达式的计值过程 一个表达式的中缀式和对应的后缀式是等价的,即表达式的计算顺序和结果完全相同。但在后缀式中没有了据号,运算符紧跟在两个操作数后面,所有的计算按运算符出现的顺序,严格从左向右进行,而不必考虑运算符的优先规则。后缀式的计值只需一个操作 数栈。 编译程序在扫描后缀表达式时,若析取一个操作数,则立即进栈;若析取一个运算符,则将操作数栈的桂顶和次楼顶连续出栈,使出楼的两个操作数执行运算符规定的运算,并将运算结果进栈。后缀表达式扫描结束时,操作数栈的栈顶内容即为表达式的值。例如后缀表达式 234+*82/一的计值过程如图 2.4所示。 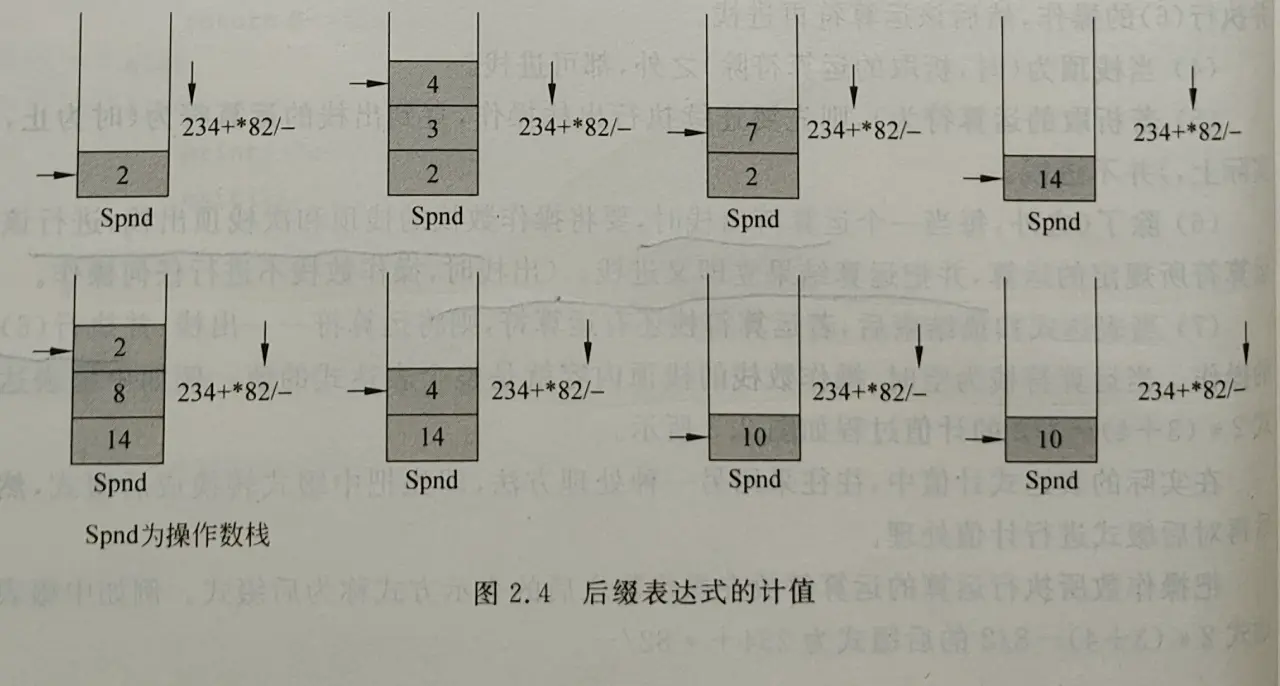 中缀表达式到后缀表达式的替换。使用一个运算符栈来存放暂时还不能确定的运算符。在扫描中缀式的过程,逐步生成后缀式。扫描到操作数时直接进入后缀式;扫描到运算符时先进栈,并按运算规则决定运算符进入后缀式的次序。操作数在后缀表达式中出现的次序与中缀表达式是相同的,运算符出现的次序就是实际就计算的次序,运算规则隐含地体现在这个顺序中。 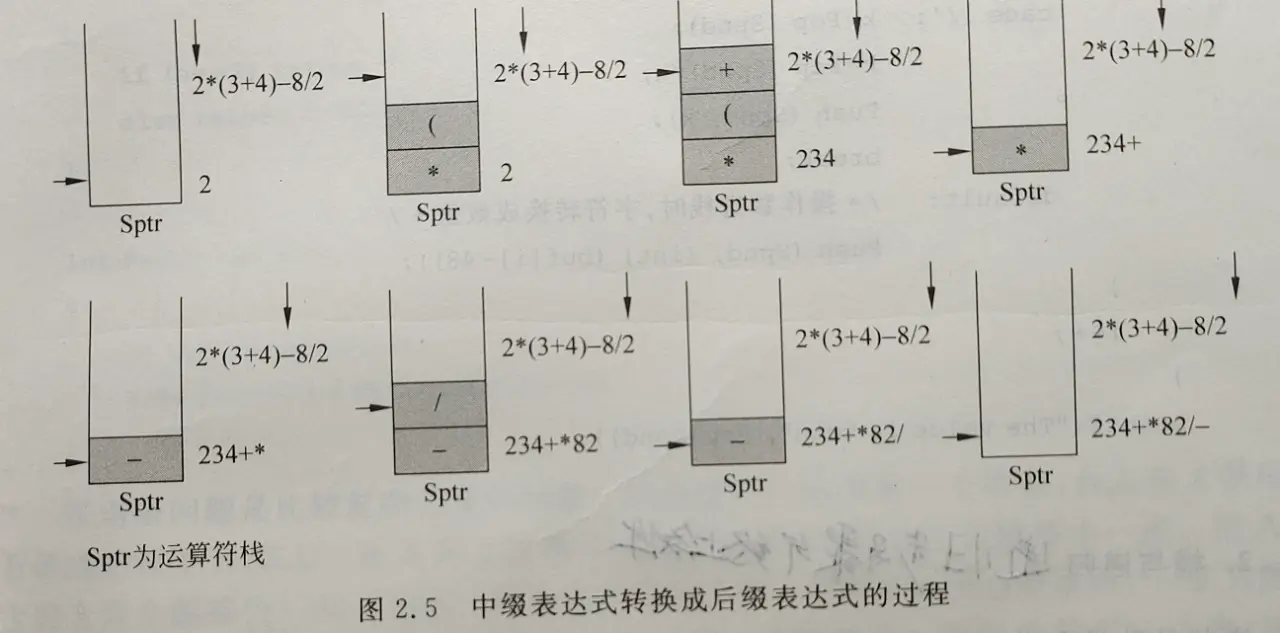 #### 递归 数学上常用的阶乘函数,幂函数,斐波那契数列都是递归的。某些数据结构,如链表,树,广义表的定义也是递归的。在这些结构上施行的操作和采用的算法也可以用递归过程实现。 递归算法的采用有两个条件。一个是较大的问题可以用较小的子问题来描述;一个是存在一个或多个无需分解、可直接求解的最小子问题。前者称为递归步骤,后者称为终止条件。最简单的递归定义是S(n)与$n!$ $S(n)= \begin{cases} 1,& n=1\\ n+S(n-1) ,& n\gt 1 \end{cases} $ $n!=\begin{cases} 1, & n=0 \\ n \times {(n-1)!}, & n \gt 0 \end{cases} $ 汉诺塔问题 第n阶的汉诺塔问题能分解为三个子汉诺塔问题。 * 把n-1个盘子从A柱移到B柱,是一个n-1阶的汉诺塔问题。 * 把一个盘子从A柱移到C柱,是一个最小汉诺塔问题。 * 把n-1个盘子从B柱移到C柱,是一个n-1阶汉诺塔问题。 递归过程在计算机中实现时必须依赖于堆栈。 递归过程在其过程内部又调用了自己,调用结束后要返回到递归过程内部本次调用语句的后继语句处。为了保证逆归过程每次调用和返回的正确执行,必须解决调用时的参数传递和返回地址保存问题。在高级语言的处理程序中,是利用一个"递归工作栈"来解决这个问题的。 每一次递归调用所需保存的信息构成一个工作记录,它基本上包括三个内容∶返回地址;即本次调用结束后应返回去执行的语句地址;本次调用时使用的实参;本层的局部变量。每进人一层递归时,系统就要建立一个新的包括上述三种信息的工作记录,并存入通归工作栈的栈顶。每退出一层递归,就从递归工作栈栈顶退出一个工作记录,由于栈的"后进先出"操作特性,这个退出的工作记录恰好是进入该层递归调用所存入的工作记录。递归调用正在执行的那一层的工作记录处于栈顶,称为活动记录。 以计算 n!的递归算法为例来说明栈在递归实现中的作用,n!的递归过程及其调用如下;  递归会导致较高的时间复杂度与空间复杂度,效率不高 ## 递归效率分析 看书吧 ## 队列 队列只允许在队尾插入,在队头删除,称为先进先出表(FIFO)。不含队列元素的队列称为空队列。 建立顺序结构队列需要为其静态分配或动态申请空间,并设置两个指针进行管理。一个指针是队头指针front,一个是队尾指针rear,指向下一个元素的存储位置。 增加和删除操作会使front与rear不断增大,最终rear增加到队列分配的连续空间之外时,队列无法再插入元素。在实际使用中,为了使队列空间能重复使用,不论插入或删除,一旦指针rear增1或front增1越出了所分配的队列空间,就让它指向这片连续空间的起始位置。指针从MaxSize-1增一变到0可用取余运算rear%MaxSize和front%Maxsize实现。同时规定循环队列最多只能有MaxSize-1个元素,以与区分空队列区分。所以,判空条件为front=rear,判满条件为front=(rear+1)%MaxSize **优先级队列** 入队顺序插入,取出最高优先级元素,实现方法见书 Last modification:January 20, 2023 © Allow specification reprint Like 如果觉得我的文章对你有用,请留下评论。